Sprache entsteht aus dem gesprochenen Wort. Wenn Du die Stimme aufnimmst, solltest Du immer auf die Sprachverständlichkeit achten.
Luft passiert die Stimmbänder und erzeugt dabei einen Klang. Durch die Steuerung der Stimmbänder können Pegel und Tonhöhe der Stimme variieren. Durch die Einwirkung der Hohlräume oberhalb der Stimmbänder (Rachen, Mund- und Nasenhöhle) wird das Spektrum der Stimme gefiltert.
Ändert man den Kraftaufwand der Stimme, ändern sich Pegel und Frequenzspektrum des Sprachtons. Sogar die Stimmlage ändert sich mit der Anstrengung. Schreien klingt anders als mit einer entspannten Stimme zu reden.
Bei Aufnahmen wirst Du feststellen, dass Spitzen eines akustischen Signals deutlich über dem RMS- oder Durchschnittspegel liegen. Stelle sicher, dass all diese Spitzen über die gesamte Aufnahmekette erhalten bleiben.
In einer nicht-tonalen Sprache sind die Konsonanten von besonderer Bedeutung. Die Konsonanten (k, p, s, t, etc.) sind überwiegend im Frequenzbereich oberhalb von 500 Hz zu finden. Genauer gesagt im Bereich von 2 kHz bis 4 kHz.
Wir empfinden die Stimme in einem Abstand von etwa einem Meter zu unserem Gesprächspartner als am natürlichsten und verständlichsten. Steht man neben oder hinter der Person, verringert sich die Natürlichkeit und Verständlichkeit.
Tatsächlich ändert sich das Spektrum der Stimme an jeder Position, während wir uns der sprechenden Person mit unserem Ohr nähern - oder einem Mikrofon.
Jede Positionierung auf dem Kopf oder der Brust hat ihre eigene Klangfarbe. Dem Spektrum von auf der Brust aufgenommener Sprache beispielsweise fehlt es in der Regel an Frequenzen im wichtigen Bereich von 2 - 4 kHz. Das führt zu einer reduzierten Sprachverständlichkeit. Wenn das Mikrofon das nicht kompensiert, solltest Du Korrekturen mit einem Equalizer vornehmen.
Sei Dir dieser Probleme bewusst, wenn Du ein Mikrofon platzierst. Wähle das richtige Mikrofon, das für die Verwendung in der gewünschten Position konzipiert ist. Anderenfalls musst Du klangliche Einbußen kompensieren (Equalizer), um den richtigen Klang zu bewahren.
Unter nachfolgendem Link findest Du ein paar kurze Videos, die Dir einen schnellen Überblick geben und wesentliche Faktoren erläutern, die Einfluss auf die Sprachverständlichkeit haben. Wenn Du allerdings tiefer in die Theorie einsteigen möchtest, solltest Du den vollständigen Artikel unter dem Video lesen.
1. Die Stimme als akustische Schallquelle
Das Verständnis der Stimme als Schallquelle ist von großer Bedeutung. Während Sprache bei ganzen Menschengruppen eine Gemeinsamkeit bilden kann, sind Klang und Charakter der Stimme von Person zu Person individuell. Gleichzeitig ist Sprache, die als akustisches Signal betrachtet wird, die Art von Klang, mit dem wir am besten vertraut sind.
Lautstärke
Stimmpegel variieren - von einem gedämpften Flüstern bis zu lautem Geschrei. Es ist schwierig, der Sprachlautstärke einen festen Wert zuzuordnen, da diese von Person zu Person individuell ist. Die Werte in der folgenden Tabelle geben den durchschnittlichen A-bewerteten Sprachpegel der Sprache eines Erwachsenen an.
Die Möglichkeit, Sprache zu verstehen, ist optimal, wenn der Sprachpegel dem Pegel normaler Sprache in einem Abstand von 1 Meter entspricht. Mit anderen Worten, einem Schalldruckpegel von etwa 55-65 dB re 20 μPa. (In diesem Fall bedeutet "re" "mit Bezug auf"; die Referenz ist der niedrigste Schalldruckpegel, der hörbar ist.)
Sprachpegel
Sprachpegel [dB re 20 µPa]
| Hörabstand [m] |
Normal |
Gehoben |
Laut |
Schrei |
| 0.25 |
70 |
76 |
82 |
88 |
| 0.5 |
65 |
71 |
77 |
83 |
| 1.0 |
58 |
64 |
70 |
76 |
| 1.5 |
55 |
61 |
67 |
73 |
| 2.0 |
52 |
58 |
64 |
70 |
| 3.0 |
50 |
56 |
62 |
68 |
| 5.0 |
45 |
51 |
57 |
63 |
Durchschnittlicher Sprachpegel als Funktion der Hör- / Aufnahmedistanz. Es gibt einen Unterschied von fast 20 dB zwischen normaler Sprache und Schreien.
Crest-Faktor
Beachte, dass jeder in der Tabelle dargestellte Pegel ein gemittelter RMS-Pegel und kein Spitzenpegel ist. Typischerweise liegen die Peaks 20-23 dB über dem Effektivwert. Das Verhältnis zwischen dem Spitzenwert und dem Effektivwert wird als Crest-Faktor bezeichnet. Dieser Faktor ist ein wichtiger Parameter, wenn eine Stimme in einem elektroakustischen System aufgezeichnet oder wiedergegeben werden soll.
Beachte auch: Lautes Singen, gemessen an den Lippen, kann Pegel von 130 dB re 20 μPa RMS und Spitzenpegel über 150 dB re 20 μPa erreichen.
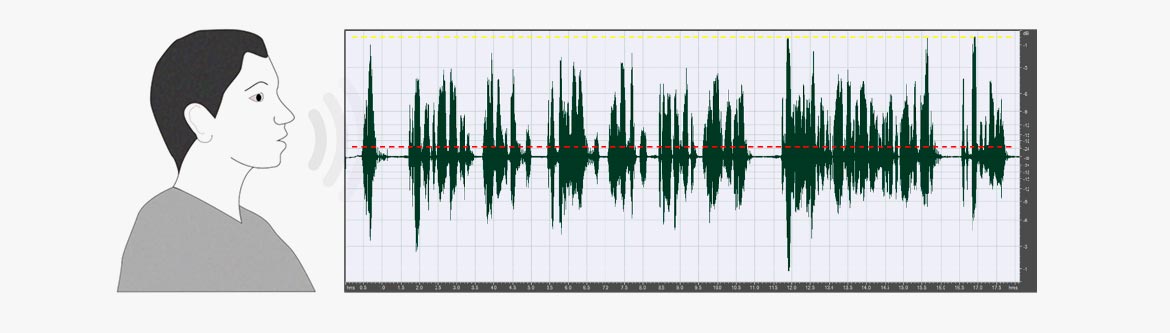 Männliche Stimme, normale Sprache (Dauer: 18 Sekunden). Durchschnittlicher RMS: -21.5 dBFS, Peak: -0.5 dBFS. Crest-Faktor 11 (21 dB). Die gepunktete rote Linie stellt den RMS-Pegel dar.
Das Spektrum der Sprache
Männliche Stimme, normale Sprache (Dauer: 18 Sekunden). Durchschnittlicher RMS: -21.5 dBFS, Peak: -0.5 dBFS. Crest-Faktor 11 (21 dB). Die gepunktete rote Linie stellt den RMS-Pegel dar.
Das Spektrum der Sprache
Das Sprachspektrum deckt einen ziemlich großen Teil des gesamten hörbaren Frequenzspektrums ab. In nicht-tonalen Sprachen kann man sagen, dass Sprache aus Vokal- und Konsonantentönen besteht. Die Vokale werden von den Stimmbändern erzeugt und von den Stimmhöhlen gefiltert. Ein Flüstern ist ohne stimmhafte Geräusche.
Die Hohlräume, die zur Bildung der verschiedenen Vokale beitragen, beeinflussen jedoch immer noch den Luftstrom. Aus diesem Grund treten die Eigenschaften von Vokalen auch im Flüsterton auf. Im Allgemeinen liegt die Grundfrequenz des komplexen Sprachtons - auch als Tonhöhe oder f0 bezeichnet - bei Männern im Bereich von 100 bis 120 Hz, es können jedoch Abweichungen außerhalb dieses Bereichs auftreten. Das f0 für Frauen liegt ungefähr eine Oktave höher. Für Kinder liegt f0 bei etwa 300 Hz.
Die Konsonanten entstehen durch Luftblockaden und Geräusche, die durch den Luftstrom durch Hals und Mund, insbesondere durch Zunge und Lippen, entstehen. In Bezug auf die Frequenz liegen die Konsonanten oberhalb von 500 Hz.
Bei einer normalen Stimmintensität nimmt die Energie der Vokale normalerweise oberhalb von ungefähr 1 kHz schnell ab. Beachte jedoch, dass sich der Schwerpunkt des Sprachspektrums um ein bis zwei Oktaven in Richtung höherer Frequenzen verschiebt, wenn die Stimme angehoben wird. Beachte auch, dass es nicht möglich ist, den Schallpegel von Konsonanten im gleichen Maße wie Vokale zu erhöhen. In der Praxis bedeutet dies, dass die Verständlichkeit der Sprache durch Schreien nicht erhöht wird, verglichen mit der Verwendung normalen Sprechens in Situationen, in denen das Hintergrundgeräusch nicht signifikant ist.
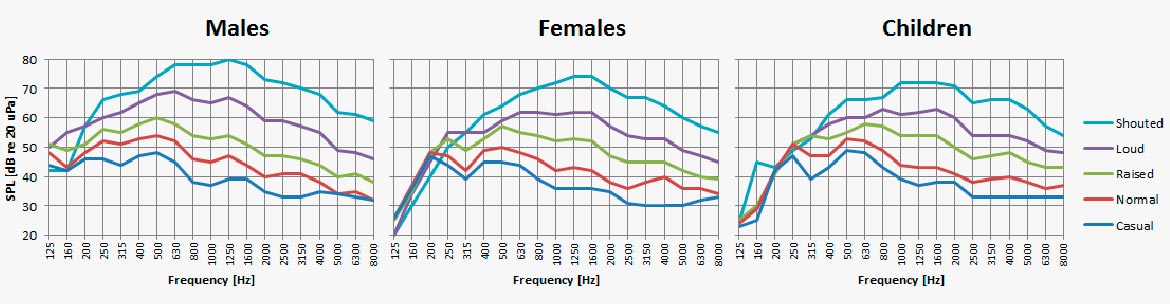 Sprachspektren (1/3 Oktave) in Abhängigkeit des Kraftaufwands.
Formanten
Sprachspektren (1/3 Oktave) in Abhängigkeit des Kraftaufwands.
Formanten
Wenn zwei Personen denselben Vokal auf derselben Tonhöhe sprechen oder singen (f0), sind die Vokale vermutlich in beiden Fällen als identisch erkennbar. Zwei beliebige Stimmen erzeugen jedoch nicht unbedingt genau das gleiche Spektrum. Die Formanten formen die wahrgenommenen Vokalklänge. Außerdem liefern die Formanten von Sprecher zu Sprecher unterschiedliche Informationen. Die Formanten werden durch die akustische Filterung des von den Stimmbändern erzeugten Spektrums geformt. Vokale entstehen durch das „Tuning“ der Resonanzen der Hohlräume im Vokaltrakt.
2. Was beeinflusst die Sprachverständlichkeit?
In tonalen Sprachen wie Chinesisch oder Thailändisch verwenden die Sprecher einen lexikalischen Ton oder eine Grundfrequenz, um die Bedeutung zu signalisieren.
In nicht-tonalen Sprachen wie Englisch, Spanisch, Japanisch, etc. unterscheiden sich Wörter durch Änderung eines Vokals, eines Konsonanten oder beidem. Von diesen beiden sind die Konsonanten jedoch am wichtigsten.
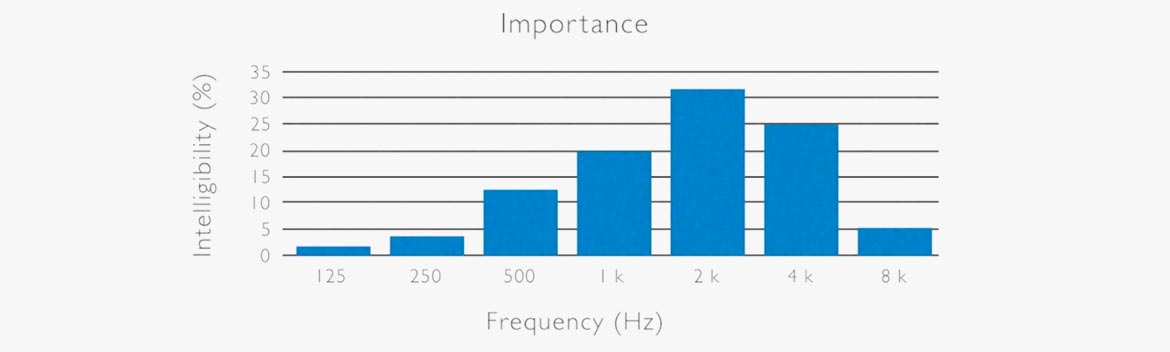
Wichtige Frequenzen
Die richtigen Frequenzen in der nicht-tonalen (westlichen) Sprache sind im folgenden Diagramm illustriert. Das Frequenzband um 2 kHz ist hier der wichtigste Frequenzbereich in Bezug auf die wahrgenommene Verständlichkeit. Die meisten Konsonanten befinden sich in diesem Frequenzband.
(Ref: N.R. French & J.C. Steinberg: Factors governing the intelligibility of speech sounds. JASA vol. 19, No 1, 1947).
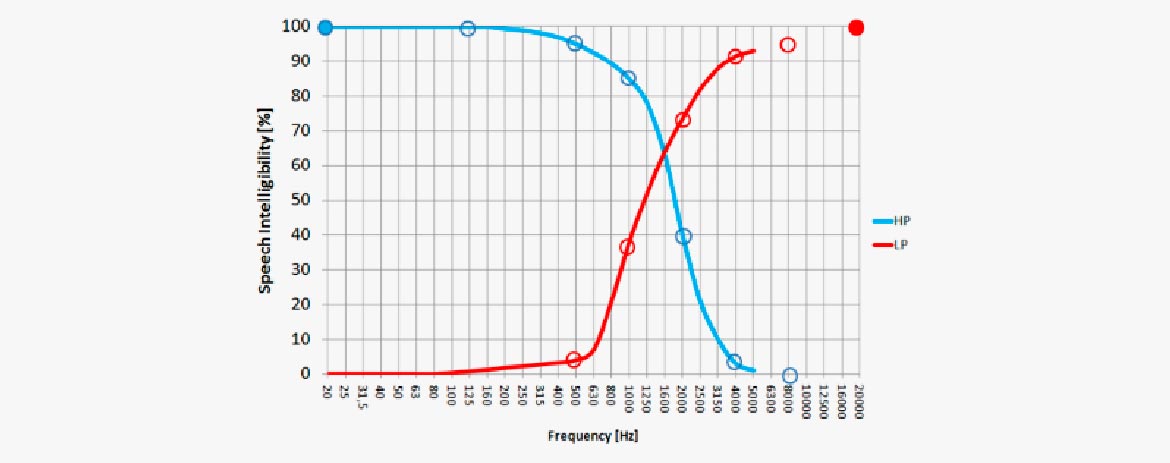
Ein Sprachspektrum ist weder hochpass- noch tiefpassgefiltert. Der Einsatz eines HP-Filters mit 20 kHz (oben links) macht die Sprache zu 100% verständlich. (Das liegt daran, dass das gesamte Sprachspektrum vorhanden ist). Ein HP-Filter, der alles unterhalb von 500 Hz abschneidet, lässt das Sprachsignal immer noch verständlich. Selbst, wenn die meiste Sprachenergie abgeschnitten wird, wird die Verständlichkeit um lediglich 5% reduziert. Eine höhere Einsatzfrequenz lässt die Verständlichkeit jedoch schnell abfallen.
Umgekehrt lässt der Einsatz eines LP-Filters die Verständlichkeit sehr schnell fallen. Bei einer Einsatzfrequenz von 1 kHz ist sie bereits auf weniger als 40% reduziert. Es ist erkennbar, dass der Frequenzbereich zwischen 1 kHz und 4 kHz für die Verständlichkeit von großer Bedeutung ist.
 Hintergrundgeräusche
Hintergrundgeräusche
Hintergrundgeräusche haben einen Einfluss auf die wahrgenommene Verständlichkeit eines Sprachsignals. In diesem Fall können alle Signale außer der Sprache selbst als Rauschen in Betracht gezogen werden. In einem Auditorium oder Klassenzimmer können Klimaanlage und andere laute Geräusche die Sprachverständlichkeit negativ beeinflussen. Auch die Anwesenheit anderer Personen verursacht Geräusche. Bei Fernseh- oder Filmton ist es sehr oft eine Frage der Balance zwischen Dialogpegel und Lautstärke der Hintergrundmusik bzw. Umgebungssounds.
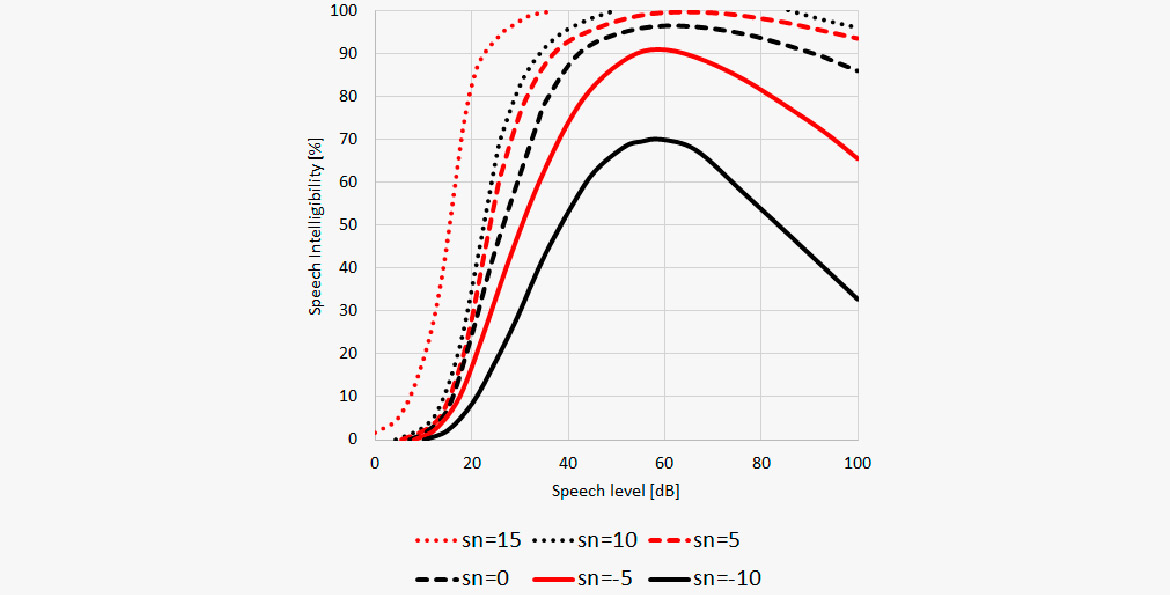 In diesem Diagramm ist die Sprachverständlichkeit gegenüber des Signal-Rausch-Abstands (S/N) dargestellt. Die untere Kurve zeigt, dass Sprache bis zu einem gewissen Grad noch verstanden werden kann, selbst wenn das S/N-Verhältnis negativ ist, was bedeutet, dass Störgeräusche 10 dB lauter sind als der Sprachpegel. Ein wahrgenommener Sprachpegel von etwa 60 dB re 20 μPa ist optimal.
In diesem Diagramm ist die Sprachverständlichkeit gegenüber des Signal-Rausch-Abstands (S/N) dargestellt. Die untere Kurve zeigt, dass Sprache bis zu einem gewissen Grad noch verstanden werden kann, selbst wenn das S/N-Verhältnis negativ ist, was bedeutet, dass Störgeräusche 10 dB lauter sind als der Sprachpegel. Ein wahrgenommener Sprachpegel von etwa 60 dB re 20 μPa ist optimal.
In diesem Gebiet wurde bereits viel geforscht. Die Ergebnisse zeigen im Allgemeinen:
- Der optimale Sprachpegel ist konstant, wenn der Hintergrundgeräuschpegel unter 40dB(A) liegt.
- Der optimale Sprachpegel scheint ein S/N-Verhältnis von 15dB(A) aufzuweisen, wenn der Hintergrundhgeräuschpegel über 40 dB(A) liegt.
- Verständnisschwierigkeiten nehmen bei ansteigendem Sprachpegel zu, wenn das S/N-Verhältnis ausreicht, um eine nahezu perfekte Sprachverständlichkeit beizubehalten.
Weiterhin sollte der Bereich von 1 - 4 kHz weitestgehend sauber bleiben. Wenn beispielsweise Musik als Hintergrund für eine Erzählung hinzugefügt wird, verbessert der Einsatz eines parametrischen Equalizers Absenkung der Musik um 5 - 10 dB in diesem Frequenzbereich die Verständlichkeit.
Nachhall
Nachhall wird in Bezug auf Sprachverständlichkeit als Störgeräusch betrachtet. Ein wenig Hall kann die Sprache unterstützen, aber sobald die Konsonanten verschmieren, leidet die Verständlichkeit.
3. Das Schallfeld
Das Schallfeld um eine sprechende Person wird nicht nur von der Physik des Stimmapparates, sondern auch von Kopf und Körper der Person beeinflusst.
Richtwirkung
Im Folgenden sind Polardiagramme eines menschlichen Sprechers in vertikaler und horizontaler Ebene dargestellt.
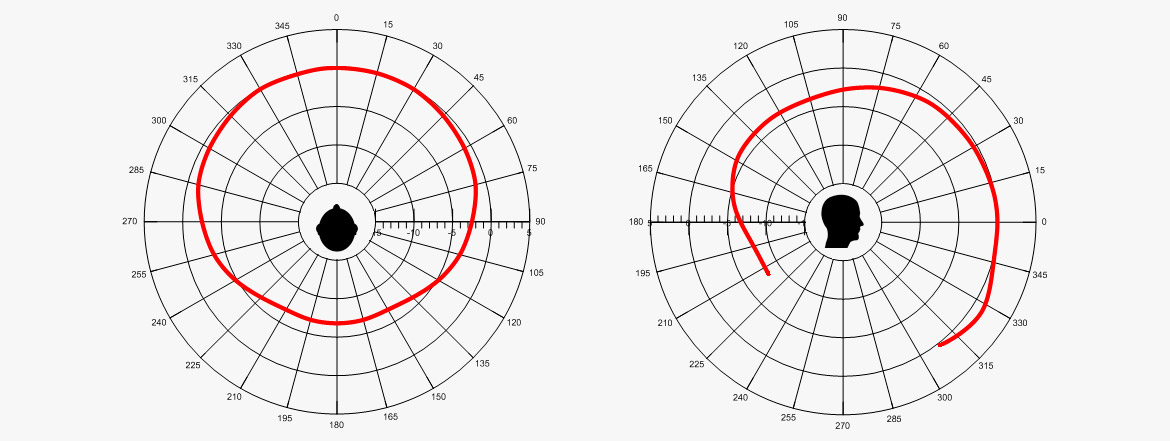 Polardiagramm eines menschlichen Sprechers. (Ref.: Chu, W.T.; Warnock, A.A.C.: Detailed Directivity of Sound Fields Around Human Talkers.)
Polardiagramm eines menschlichen Sprechers. (Ref.: Chu, W.T.; Warnock, A.A.C.: Detailed Directivity of Sound Fields Around Human Talkers.)
Die abgebildeten Pegel sind A-bewertet und gelten für Männer und Frauen gleichermaßen. Alle Sprecher saßen. Die Pegel wurden im Anstand von 1 Meter ermittelt. Wie ersichtlich liegt der Unterschied zwischen Vorder- und Rückseite bei etwa 7 dB. Dies sagt jedoch nichts über die Frequenzabhängigkeit aus: hohe Frequenzen sind auf der Rückseite gedämpfter als tiefe Frequenzen.
Bitte beachte, dass der Pegel in der vertikalen Ebene bei 330° höher ist als bei anderen Winkeln. Dies liegt hauptsächlich daran, dass der Schall von der Brust reflektiert wird.
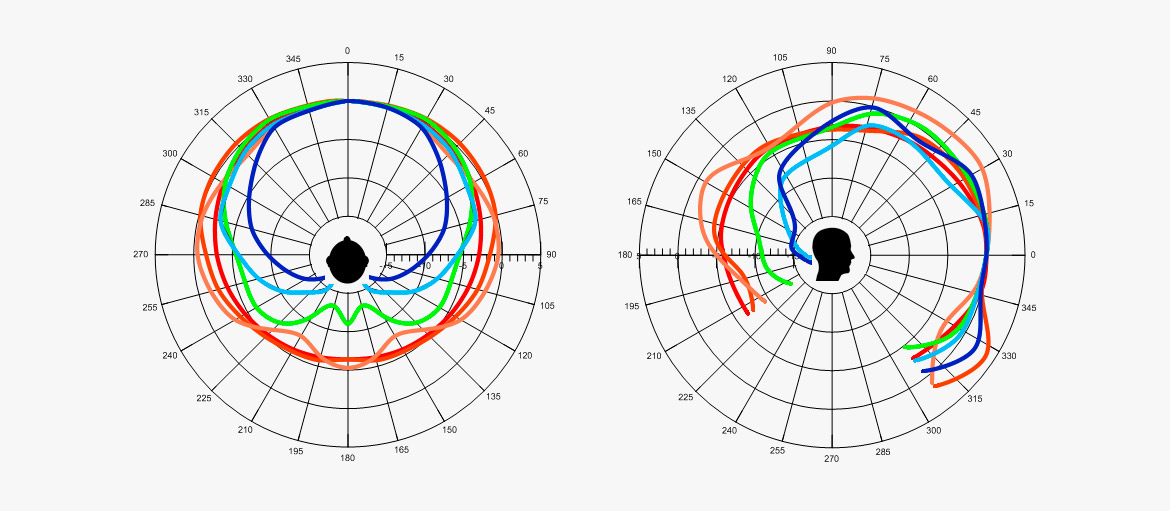 Dieses Diagramm zeigt die frequenzabhängige Polardiagramme von 160 Hz bis 8 kHz.
Dieses Diagramm zeigt die frequenzabhängige Polardiagramme von 160 Hz bis 8 kHz.
Es zeigt, dass die Richtwirkung ab etwa 1 kHz zunimmt. Kombiniert man diese Tatsache mit der Bedeutung von Frequenzen oberhalb von 1 kHz wird es deutlich, dass bei der Aufnahme vor einer Person eine höhere Sprachverständlichkeit erreicht wird als hinter ihr.
Polardiagramm eines menschlichen Sprechers, 1/3-Oktav-Intervalle. Unterteilung 5 dB. (Ref.: Chu, W.T.; Warnock, A.A.C.: Detailed Directivity of Sound Fields Around Human Talkers.)
Abstand und Richtung
Da nicht alle Mikrofone im Abstand von 1 Meter vom Sprecher platziert werden, ist es interessant zu wissen, was passiert, wenn wir näher an die Schallquelle herangehen.
Die folgenden Diagramme zeigen die spektrale Abweichung der Sprache im Abstand von 1 Meter zum angegebenen Winkel. Die Winkel (+45 Grad, 0 Grad und -45 Grad) liegen n der vertikalen Ebene. Die Ergebnisse wurden über 10 Sprecher gemittelt.
Die Linien in jedem der drei Diagramme zeigen die Abweichung bei 80 cm, 40 cm, 20 cm und 10 cm.
Wenn es keine Änderungen im Spektrum gäbe, entsprächen alle Kurvenverläufe geraden Linien. Die Abweichungen nehmen aber zu, wenn wir näher an den Sprecher gehen.
Die obere Abbildung stellt die Messung in Position 45° über der Achse dar. Die Abweichung hier ist subtil. Deshalb bietet die Mikrofonierung mit der Tonangeln über Kopf ein stabiles Spektrum, das nicht so abhängig von der Entfernung ist.
Die untere Abbildung zeigt was geschieht, wenn wir die Stimme unterhalb der Achsenebene einfangen. Der Einfluss des vom Körper reflektierten Schalls ist erheblich.
Die Abweichungen auf der Achse liegen irgendwo zwischen den beiden anderen, was bedeutet, dass das Spektrum der Sprache sich mit dem Abstand zum Mikrofon ändert.
 (Ref: Brixen, Eddy B.: Near field registration of the human voice: Spectral changes due to positions. AES Convention 104, Amsterdam, the Netherlands. Preprint 4728)
Kopf und Brust
(Ref: Brixen, Eddy B.: Near field registration of the human voice: Spectral changes due to positions. AES Convention 104, Amsterdam, the Netherlands. Preprint 4728)
Kopf und Brust
Bei Rundfunk- und Live-Sound-Anwendunge werden Lavaliermikrofone (an der Brust) oder Kopfbügelmikrofone (am Kopf) bevorzugt eingesetzt, da sie eine größere Bewegungsfreiheit erlauben. Dabei sollte man sich bewusst sein, dass die Platzierung des Mikrofons auf so kurze Distanz ein Aufnahmespektrum erzeugt, das von dem üblichen Spektrum bei normalem Hör-Abstand abweicht. Diese Abweichung ist keineswegs vernachlässigbar.
Im Folgenden sind fünf Abbildungen dargestellt, die erklären, was mit dem Sprachspektrum passiert, wenn die Mikrofone am Körper oder am Kopf platziert werden. Alle kurven basieren auf Messungen und sind über 10 Personen gemittelt (s. Ref.).
Die obere Kurve (Brust) zeigt den Unterschied zwischen dem an der Brust aufgenommenen Sprachspektrum und dem der Sprache derselben Person im Abstand von 1 Meter auf der Achse. Wenn das Mikrofon an der Brust platziert wird, werden die Frequenzen im kritischen Bereich von 2 - 4 kHz erheblich reduziert.
Die zweite Kurve (Hals) zeigt die Abweichung, wenn sich das Mikrofon noch näher befindet, direkt unterhalb des Kinns. Diese Position ist im Rundfunkbereich sehr verbreitet, da sie die einzige Möglichkeit bietet, ein Lavaliermikrofon zu platzieren, wenn der Journalist oder Interviewpartner ein T-Shirt, Sweatshirt und dergleichen oder einen Mantel trägt. Für den Außeneinsatz kann das Mikrofon mit einem Fellwindschutz versehen oder hinter der Krawatte angebracht werden. Hier gibt es in jedem Fall einen starken Abfall bei den Frequenzen der Konsonanten.
Die Stirn-Kurve belegt, dass die Platzierung des Mikrofons an der Stirn die unauffälligsten spektralen Abweichungen mit sich bringt. Diese Position ist perfekt für Bühne und Film, eignet sich aber nicht für Berichterstattung.
Die Ohr-Kurve seigt einen leichten Abfall hoher Frequenzen bei dieser Platzierung. Es kann sehr bequem sein, das Mikrofon am Ohr zu platzieren. Es ist jedoch eine Kompensation erforderlich, um die Sprachverständlichkeit zu erhalten.
Bei der Platzierung des Mikrofons am Kinn (Headset), verhält sich der Bereich von 2 - 4 kHz besser als die meisten anderen Positionen. Hier besteht jedoch Bedarf an einer kleinen Anhebung der höchsten Frequenzen. Kopfbügelmikrofone von DPA haben bereits eine eingebaute Anhebung.
Es sollte noch erwähnt werden, dass der Sprachpegel im Mundwinkel etwa 10 dB höher ist verglichen mit der Positionierung an der Brust.
An diesen Kurven kann man gut ablesen, dass eine allgemeine Anhebung im Bereich um die 800 Hz auftritt, die man kompensieren kann. Die wesentliche Abweichung ist aber die Dämpfung, die die Sprachverständlichkeit beeinflusst. Diese muss stets beachtet werden!




 (Ref: Brixen, Eddy B.: Spectral degradation of speech captured by miniature microphones mounted on Persons’ heads and chests. AES Convention no. 100, Copenhagen, Denmark. Preprint 4284.)
(Ref: Brixen, Eddy B.: Spectral degradation of speech captured by miniature microphones mounted on Persons’ heads and chests. AES Convention no. 100, Copenhagen, Denmark. Preprint 4284.)
4. Platzierung des Mikrofons
Unter diesen Bedingungen kann eine Reihe von Regeln festgelegt werden für die Auswahl und Platzierung eines Mikrofons, wenn die Sprachverständlichkeit von Bedeutung ist.
Handmikrofon für Gesang
- Gesangsmikrofone sollten vor dem Mund in einem Winkel von ±30° positioniert werden.
- Bei Verwendung eines Mikrofons mit Richtwirkung (Nieren-Typ oder Shotgun), sollte es auf der Achse verwendet werden (und nicht wie eine Eiswaffel).
- Zu dichte Windschütze können einen weiteren Höhenverlust verursachen. Beachte, diesen zu kompensieren.
Lavalier / Brustplatziertes Mikrofon
Das Sprachspektrum bei der typischen Brust-Positionierung weist einen Mangel im wichtigen Frequenzbereich von 3 - 4 kHz auf. Wenn ein Mikrofon mit einem linearen Frequenzgang an der Brust einer Person platziert wird, sollte der Bereich von 3 - 4 kHz etwa 5 - 10 dB angehoben werden, um den Verlust zu kompensieren.
- In der Praxis gibt es zwei Lösungen: Verwende ein Mikrofon, das zur Kompensation bereits vorentzerrt ist, oder denke daran, bei der Bearbeitung die richtige Entzerrung vorzunehmen. Beachte, dass kein ENG-Mischer oder Kameras automatisch kompensieren und keine Regelmöglichkeiten vorsehen, dies zu tun. In vielen Fällen wird der Frequenzgang nie angeglichen, daher ist die Verständlichkeit oft schlecht.
Kopfbügelmikrofone
- Der Pegel eines Kopfbügelmikrofons ist etwa 10 dB höher am Kinn verglichen mit der Brustposition.
- Das Spektrum ist im Vergleich zur Brustposition weniger betroffen. Allerdings muss zu einem gewissen Grad der Abfall der hohen Frequenzen kompensiert werden.
- Eine Stirn-Position (nah am Haaransatz), wie sie oft im Bereich Film und Bühnendarbietung verwendet wird, ist vergleichsweise neutral in Bezug auf Sprachverständlichkeit.
Podiumsmikrofone
- Podiumsmikrofone werden oft in verschiedenen Abständen eingesetzt. Daher sollten die Mikrofone eine Richtwirkung aufweisen, insbesondere im Frequenzbereich overhalb von 1 kHz.
- Das Mikrofon muss auf den Mund des Sprechers gerichtet sein.
- Mikrofone, die in ein Podium eingelassen sind, sollten unempfindlich gegenüber Vibrationen und Körperschall sein.
Panel-Mikrofone (mehrere Sprecher)
- Platziere jedes Mikrofon so nah wie möglich an den jeweiligen Sprecher.
- Wähle gerichtete Mikrofone.
- Wenn mehr als eine Person zur gleichen Zeit spricht, sollte das Mikrofon der Sprecher den Ton der anderen Sprecher um mindestens 10 dB dämpfen.
Booming
- Beim Booming wird das neutralste Spektrum erreicht, wenn das Mikrofon vor und über dem Kopf platziert wird.
- Wenn das Umfeld es erlaubt, können andere Mikrofone als Shotguns verwendet werden.
Laute / hallige Umgebung
- Positioniere das Mikrofon näher an die primäre Schallquelle (den Mund des Sprechers).
- Verwende ein Mikrofon mit einer hohen Unterdrückung von Einstreuungen, typischerweise eine Niere / Superniere.
Zusammenfassung

Wenn Du Dir die oben genannte Theorie noch einmal in einem Video anschauen möchtest, gibt es hier den Mitschnitt einer Facebook Live Veranstaltung vom 6. Mai 2020:
facebook.com/46360195734/videos/515010452527552/